2025/3/19
This commit is contained in:
109
技术/Redis/Redis.md
Normal file
109
技术/Redis/Redis.md
Normal file
@@ -0,0 +1,109 @@
|
||||
## 常见的几种网络模型?
|
||||
### 阻塞 IO
|
||||
|
||||
- 过程 1:应用程序想要去读取数据,他是无法直接去读取磁盘数据的,他需要先到内核里边去**等待内核操作硬件**拿到数据,这个等待数据就绪的过程便是过程1。
|
||||
|
||||
- 过程 2:内核态准备好了,开始拷贝数据给用户缓冲区,便是过程2。 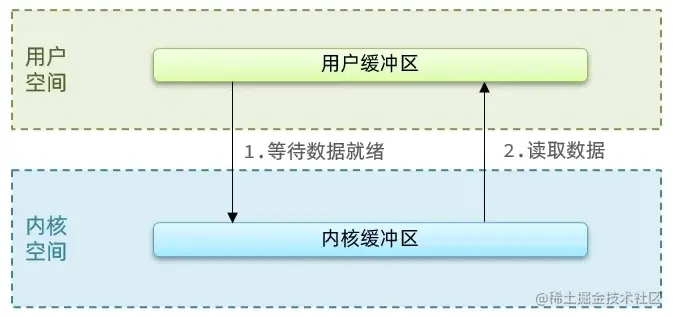
|
||||
|
||||
|
||||
用户去读取数据时,会去先发起 `recvform` 一个命令,去尝试从内核上加载数据,如果内核没有数据,那么用户就会等待,此时内核会去从硬件上读取数据,内核读取数据之后,会把数据拷贝到用户态,并且返回 ok,整个过程,都是阻塞等待的,这就是阻塞 IO
|
||||
|
||||
> 也就是两个过程都阻塞的话,便是阻塞IO
|
||||
|
||||
### 非阻塞 IO
|
||||
顾名思义,非阻塞 IO 的 **recvfrom 操作会立即返回结果**而不是阻塞用户进程。
|
||||
|
||||
阶段一:
|
||||
|
||||
- 用户进程尝试读取数据(比如网卡数据)
|
||||
- 此时数据尚未到达,内核需要等待数据
|
||||
- 返回**异常**给用户进程
|
||||
- **用户进程收到 error 后,再次尝试读取【忙轮询】**
|
||||
- 循环往复,直到数据就绪
|
||||
|
||||
阶段二:
|
||||
|
||||
- 将内核数据拷贝到用户缓冲区
|
||||
- 拷贝过程中,用户进程**依然阻塞等待**
|
||||
- 拷贝完成,用户进程解除阻塞,处理数据
|
||||
|
||||
> 可以看到,非阻塞 IO 模型中,用户进程在**第一个阶段是非阻塞,第二个阶段是阻塞状态**。虽然是非阻塞,但性能并没有得到提高。而且**忙等机制**会导致 **CPU 空转,CPU 使用率暴增。**
|
||||
|
||||

|
||||
|
||||
### 信号驱动
|
||||
|
||||
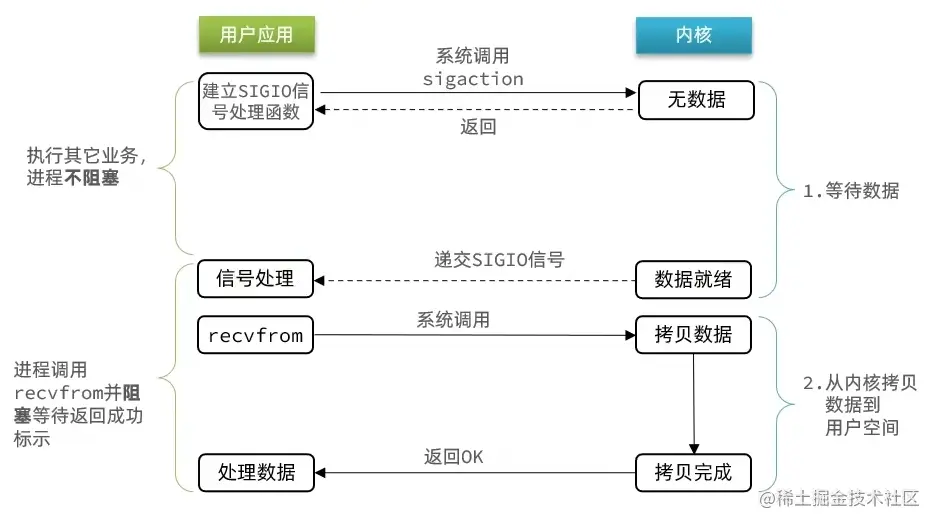
信号驱动 IO 是与内核建立 SIGIO 的信号关联并设置回调,当内核有 FD 就绪时,会发出 SIGIO 信号通知用户,期间用户应用可以执行其它业务,无需阻塞等待。
|
||||
|
||||
阶段一:
|
||||
|
||||
- 用户进程调用 sigaction ,**注册信号处理函数**
|
||||
- 内核返回成功,开始监听 FD
|
||||
- 用户进程不阻塞等待,可以执行其它业务
|
||||
- 当内核数据就绪后,回调用户进程的 SIGIO 处理函数
|
||||
|
||||
阶段二:
|
||||
|
||||
- 收到 SIGIO 回调信号
|
||||
- 调用 recvfrom ,读取
|
||||
- 内核将数据拷贝到用户空间
|
||||
- 用户进程处理数据
|
||||
|
||||
|
||||
|
||||
#### 缺点
|
||||
|
||||
当有大量 IO 操作时,信号较多,SIGIO 处理函数不能及时处理可能导致**信号队列溢出**,而且内核空间与用户空间的频繁信号交互性能也较低。
|
||||
|
||||
|
||||
### IO多路复用
|
||||
|
||||
IO多路复用的实现可以通过操作系统提供的不同系统调用来实现,其中最常用的有**select**、**poll**和**epoll**。
|
||||
|
||||
1. **select**: select是最古老的IO多路复用机制,它使用一个文件描述符集合来监听多个IO事件的就绪状态。应用程序需要将需要监听的文件描述符添加到集合中,然后调用select函数进行监听。当有文件描述符就绪时,select函数会返回,并告知哪些文件描述符已经准备好进行读取或写入操作。然后应用程序可以通过遍历文件描述符集合来处理就绪的IO事件。
|
||||
|
||||
2. **poll**: poll是select的改进版本,它也使用一个文件描述符集合来监听多个IO事件的就绪状态。与select不同的是,poll不需要每次调用都将文件描述符集合传递给内核,而是使用一个pollfd结构体数组来传递。应用程序需要将需要监听的文件描述符和事件类型添加到pollfd数组中,然后调用poll函数进行监听。当有文件描述符就绪时,poll函数会返回,并告知哪些文件描述符已经准备好进行读取或写入操作。然后应用程序可以通过遍历pollfd数组来处理就绪的IO事件。
|
||||
|
||||
3. **epoll**: epoll是Linux特有的IO多路复用机制,它使用一个内核事件表来管理和监听多个IO事件的就绪状态。应用程序需要将需要监听的文件描述符添加到内核事件表中,然后调用epoll_wait函数进行监听。当有文件描述符就绪时,epoll_wait函数会返回,并告知哪些文件描述符已经准备好进行读取或写入操作。与select和poll不同的是,epoll使用回调函数来处理就绪的IO事件,而不需要应用程序遍历事件列表。
|
||||
|
||||
| **机制** | **原理** | **优点** | **缺点** |
|
||||
| ---------- | ---------------------------- | ------------------ | ------------------------- |
|
||||
| **select** | 轮询所有描述符,返回就绪的集合 | 跨平台兼容性好 | 描述符数量受限(通常 1024),性能随连接数下降 |
|
||||
| **poll** | 类似`select`,但使用链表存储描述符,无数量限制 | 解决文件描述符数量限制 | 仍需轮询,效率低(O(n) 复杂度) |
|
||||
| **epoll** | 事件驱动机制,仅返回就绪的描述符,通过红黑树和事件表优化 | 高效处理万级连接(O(1) 复杂度) | 仅适用于 Linux |
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## 跳表
|
||||
|
||||
通过建立索引的方式,对于数据量越大的有序链表,通过建立多级索引,查找效率提升会非常明显。
|
||||
这种**链表加多级索引的结构** 就是 **跳表**。
|
||||
|
||||
Redis中的 有序集合 **zset** 就是用跳表实现的。
|
||||
|
||||
> **跳表中操作的时间复杂度**就是**O(logn).** 与二分查找的时间复杂度相同。
|
||||
|
||||
基于单链表实现了二分查找,查询效率的提升依赖构建了多级索引,是一种空间换时间的设计思路。
|
||||
|
||||

|
||||
|
||||
## MySQL为什么用B+树,而不是跳表
|
||||
|
||||
**MySQL是持久化数据库、即存储到磁盘上,因此查询时要求更少磁盘 IO,且 Mysql 是读多写少的场景较多,显然 B+ 树更加适合Mysql。**[[MySQL相关#B+索引]]
|
||||
|
||||
Redis是直接操作内存的、并不需要磁盘io;而MySQL需要去读取磁盘io,所以MySQL使用b+树的方式去减少磁盘io。B+树原理是 叶子节点存储数据、非叶子节点存储索引,每次读取磁盘页时就会读取一整个节点,每个叶子节点还要指向前后节点的指针,其目的是最大限度地降低磁盘io
|
||||
|
||||
数据在内存中读取 耗费时间是磁盘IO读取的百万分之一,而Redis是内存中读取数据、不涉及IO,因此使用了跳表,跳表模型是更快更简单的方式
|
||||
|
||||
- **时间复杂度优势**:跳表是一种基于链表的数据结构,可以在O(log n)的时间内进行插入、删除和查找操作。而B树需要维护平衡,操作的时间复杂度较高,通常为O(log n)或者更高。在绝大多数情况下,跳表的性能要优于B树。
|
||||
- **简单高效**:跳表的实现相对简单,并且容易理解和调试。相比之下,B树的实现相对复杂一些,需要处理更多的情况,例如节点的分裂和合并等操作。
|
||||
- **空间利用率高**:在关键字比较少的情况下,跳表的空间利用率要优于B树。B树通常需要每个节点存储多个关键字和指针,而跳表只需要每个节点存储一个关键字和一个指针。
|
||||
- **并发性能好**:跳表的插入和删除操作比B树更加简单,因此在并发环境下更容易实现高性能。在多线程读写的情况下,跳表能够提供较好的并发性能。
|
||||
## Hash、B+树、跳表的比较
|
||||
|数据结构|实现原理|key查询方式|查找效率|存储大小|插入、删除效率|
|
||||
|---|---|---|---|---|---|
|
||||
|Hash|哈希表|支持单key|接近O(1)|小,除了数据没有额外的存储|O(1)|
|
||||
|B+树|平衡二叉树扩展而来|单key,范围,分页|O(logn)|除了数据,还多了左右指针,以及叶子节点指针|O(logn),需要调整树的结构,算法比较复杂|
|
||||
|跳表|有序链表扩展而来|单key,分页|O(logn)|除了数据,还多了指针,但是每个节点的指针小于<2,所以比B+树占用空间小|O(logn),只用处理链表,算法比较简单
|
||||
Reference in New Issue
Block a user