2025-03-20-02
This commit is contained in:
@@ -106,4 +106,64 @@ Redis是直接操作内存的、并不需要磁盘io;而MySQL需要去读取
|
||||
|---|---|---|---|---|---|
|
||||
|Hash|哈希表|支持单key|接近O(1)|小,除了数据没有额外的存储|O(1)|
|
||||
|B+树|平衡二叉树扩展而来|单key,范围,分页|O(logn)|除了数据,还多了左右指针,以及叶子节点指针|O(logn),需要调整树的结构,算法比较复杂|
|
||||
|跳表|有序链表扩展而来|单key,分页|O(logn)|除了数据,还多了指针,但是每个节点的指针小于<2,所以比B+树占用空间小|O(logn),只用处理链表,算法比较简单
|
||||
|跳表|有序链表扩展而来|单key,分页|O(logn)|除了数据,还多了指针,但是每个节点的指针小于<2,所以比B+树占用空间小|O(logn),只用处理链表,算法比较简单
|
||||
## Redis的过期删除策略
|
||||
Redis 是可以对 key 设置过期时间的,因此需要有相应的机制将已过期的键值对删除,而做这个工作的就是过期键值删除策略
|
||||
|
||||
Redis整体的删除策略是**惰性删除+定期删除**这两种策略配合使用
|
||||
|
||||
### 什么是惰性删除
|
||||
惰性删除的做法是:
|
||||
**不主动删除过期Key,每次从数据库访问Key时,都检测Key是否过期,如果过期就删除该Key**
|
||||
|
||||
- 惰性删除优点:
|
||||
- 对CPU时间友好,节省资源,防止短时间占用大量资源。
|
||||
- 惰性删除缺点:
|
||||
- 冷数据难以被删除,甚至一直留存在内存中,造内存空间浪费。
|
||||
|
||||
### 什么是定期删除
|
||||
|
||||
|
||||
定期删除的策略是:
|
||||
**每隔一段时间随机从数据库中取出一批数据进行检查,并删除其中过期的Key**
|
||||
|
||||
1. 定时serverCron方法去执行清理,执行频率根据redis.conf中的hz配置的值
|
||||
2. 执行清理的时候,不是去扫描所有的key,而是去扫描所有设置了过期时间的key(redisDb.expires)
|
||||
3. 如果每次去把所有过期的key都拿过来,那么假如过期的key很多,就会很慢,所以也不是一次性拿取所有的key
|
||||
4. 根据hash桶的维度去扫描key,扫到20(可配)个key为止。假如第一个桶是15个key ,没有满足20,继续扫描第二个桶,第二个桶20个key,由于是以hash桶的维度扫描的,所以第二个扫到了就会全扫,总共扫描35个key
|
||||
5. 找到扫描的key里面过期的key,并进行删除
|
||||
6. 删除完检查过期的 key 超过 25%,继续执行4、5步
|
||||
|
||||

|
||||
|
||||
## redis内存淘汰策略
|
||||
|
||||
我们设置完redis内存之后,我们就像里面放数据,但是内存总有满的时候,满的时候redis又是怎么处理的呢?
|
||||
|
||||
每进行一次redis操作的时候,redis都会检测可用内存,判断是否要进行内存淘汰,当超过可用内存的时候,redids 就会使用对应淘汰策略。
|
||||
|
||||
有以下几种内存淘汰策略:
|
||||
### 1.no-envicition:
|
||||
该策略对于写请求不再提供服务,会直接返回错误,当然排除del等特殊操作,**redis默认是no-envicition**策略。
|
||||
### 2.allkeys-random:
|
||||
从redis中随机选取key进行淘汰
|
||||
### 3.allkeys-lru:
|
||||
使用LRU(Least Recently Used,最近最少使用)算法,从redis中选取使用最少的key进行淘汰
|
||||
### 4.volatile-random:
|
||||
从redis中设置过过期时间的key,进行随机淘汰
|
||||
### 5.volatile-ttl:
|
||||
从redis中选取即将过期的key,进行淘汰
|
||||
### 6.volatile-lru:
|
||||
使用LRU(Least Recently Used,最近最少使用)算法,从redis中设置过过期时间的key中,选取最少使用的进行淘汰
|
||||
### 7.volatile-lfu:
|
||||
使用LFU(Least Frequently Used,最不经常使用),从设置了过期时间的键中选择某段时间之内使用频次最小的键值对清除掉
|
||||
### 8.allkeys-lfu:
|
||||
使用LFU(Least Frequently Used,最不经常使用),从所有的键中选择某段时间之内使用频次最少的键值对清除
|
||||
|
||||
## 布隆过滤器原理
|
||||
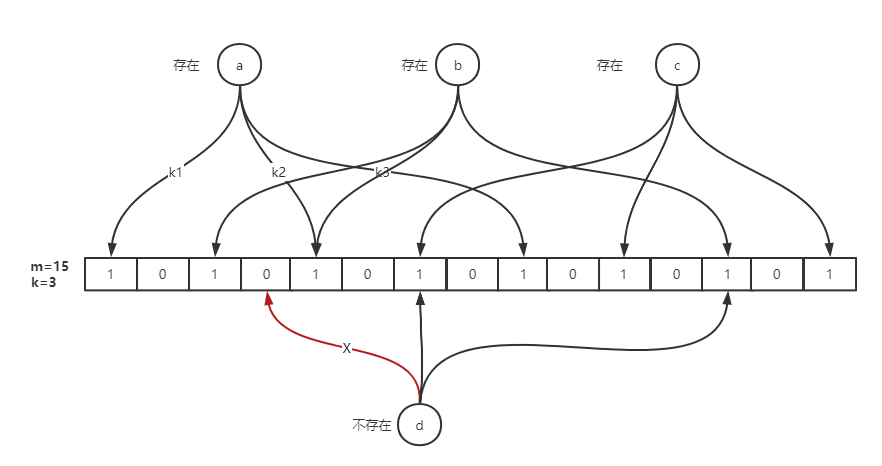
布隆过滤器的原理是,当一个元素被加入集合时,通过 **K 个散列函数** 将这个元素映射成一个位数组中的 **K 个点**,把它们置为 `1`。检索时,我们只要看看这些点是不是都是 `1` 就可以判断该元素“可能存在于集合中”。如果这些点中有任何一个为 `0`,则该元素“肯定不存在于集合中”。这种数据结构通过多个哈希函数来减少误判的概率,但仍然可能存在假阳性的情况。布隆过滤器是一种高效的空间节省的数据结构,特别适用于需要快速判断元素存在性的场景。
|
||||
|
||||
|
||||
|
||||
|
||||
##
|
||||
Reference in New Issue
Block a user