12 KiB
常见的几种网络模型?
阻塞 IO
-
过程 1:应用程序想要去读取数据,他是无法直接去读取磁盘数据的,他需要先到内核里边去等待内核操作硬件拿到数据,这个等待数据就绪的过程便是过程1。
-
过程 2:内核态准备好了,开始拷贝数据给用户缓冲区,便是过程2。
用户去读取数据时,会去先发起 recvform 一个命令,去尝试从内核上加载数据,如果内核没有数据,那么用户就会等待,此时内核会去从硬件上读取数据,内核读取数据之后,会把数据拷贝到用户态,并且返回 ok,整个过程,都是阻塞等待的,这就是阻塞 IO
也就是两个过程都阻塞的话,便是阻塞IO
非阻塞 IO
顾名思义,非阻塞 IO 的 recvfrom 操作会立即返回结果而不是阻塞用户进程。
阶段一:
- 用户进程尝试读取数据(比如网卡数据)
- 此时数据尚未到达,内核需要等待数据
- 返回异常给用户进程
- 用户进程收到 error 后,再次尝试读取【忙轮询】
- 循环往复,直到数据就绪
阶段二:
- 将内核数据拷贝到用户缓冲区
- 拷贝过程中,用户进程依然阻塞等待
- 拷贝完成,用户进程解除阻塞,处理数据
可以看到,非阻塞 IO 模型中,用户进程在第一个阶段是非阻塞,第二个阶段是阻塞状态。虽然是非阻塞,但性能并没有得到提高。而且忙等机制会导致 CPU 空转,CPU 使用率暴增。
信号驱动
信号驱动 IO 是与内核建立 SIGIO 的信号关联并设置回调,当内核有 FD 就绪时,会发出 SIGIO 信号通知用户,期间用户应用可以执行其它业务,无需阻塞等待。
阶段一:
- 用户进程调用 sigaction ,注册信号处理函数
- 内核返回成功,开始监听 FD
- 用户进程不阻塞等待,可以执行其它业务
- 当内核数据就绪后,回调用户进程的 SIGIO 处理函数
阶段二:
- 收到 SIGIO 回调信号
- 调用 recvfrom ,读取
- 内核将数据拷贝到用户空间
- 用户进程处理数据
缺点
当有大量 IO 操作时,信号较多,SIGIO 处理函数不能及时处理可能导致信号队列溢出,而且内核空间与用户空间的频繁信号交互性能也较低。
IO多路复用
IO多路复用的实现可以通过操作系统提供的不同系统调用来实现,其中最常用的有select、poll和epoll。
-
select: select是最古老的IO多路复用机制,它使用一个文件描述符集合来监听多个IO事件的就绪状态。应用程序需要将需要监听的文件描述符添加到集合中,然后调用select函数进行监听。当有文件描述符就绪时,select函数会返回,并告知哪些文件描述符已经准备好进行读取或写入操作。然后应用程序可以通过遍历文件描述符集合来处理就绪的IO事件。
-
poll: poll是select的改进版本,它也使用一个文件描述符集合来监听多个IO事件的就绪状态。与select不同的是,poll不需要每次调用都将文件描述符集合传递给内核,而是使用一个pollfd结构体数组来传递。应用程序需要将需要监听的文件描述符和事件类型添加到pollfd数组中,然后调用poll函数进行监听。当有文件描述符就绪时,poll函数会返回,并告知哪些文件描述符已经准备好进行读取或写入操作。然后应用程序可以通过遍历pollfd数组来处理就绪的IO事件。
-
epoll: epoll是Linux特有的IO多路复用机制,它使用一个内核事件表来管理和监听多个IO事件的就绪状态。应用程序需要将需要监听的文件描述符添加到内核事件表中,然后调用epoll_wait函数进行监听。当有文件描述符就绪时,epoll_wait函数会返回,并告知哪些文件描述符已经准备好进行读取或写入操作。与select和poll不同的是,epoll使用回调函数来处理就绪的IO事件,而不需要应用程序遍历事件列表。
| 机制 | 原理 | 优点 | 缺点 |
|---|---|---|---|
| select | 轮询所有描述符,返回就绪的集合 | 跨平台兼容性好 | 描述符数量受限(通常 1024),性能随连接数下降 |
| poll | 类似select,但使用链表存储描述符,无数量限制 |
解决文件描述符数量限制 | 仍需轮询,效率低(O(n) 复杂度) |
| epoll | 事件驱动机制,仅返回就绪的描述符,通过红黑树和事件表优化 | 高效处理万级连接(O(1) 复杂度) | 仅适用于 Linux |
跳表
通过建立索引的方式,对于数据量越大的有序链表,通过建立多级索引,查找效率提升会非常明显。 这种链表加多级索引的结构 就是 跳表。
Redis中的 有序集合 zset 就是用跳表实现的。
跳表中操作的时间复杂度就是O(logn). 与二分查找的时间复杂度相同。
基于单链表实现了二分查找,查询效率的提升依赖构建了多级索引,是一种空间换时间的设计思路。

MySQL为什么用B+树,而不是跳表
MySQL是持久化数据库、即存储到磁盘上,因此查询时要求更少磁盘 IO,且 Mysql 是读多写少的场景较多,显然 B+ 树更加适合Mysql。MySQL相关#B+索引
Redis是直接操作内存的、并不需要磁盘io;而MySQL需要去读取磁盘io,所以MySQL使用b+树的方式去减少磁盘io。B+树原理是 叶子节点存储数据、非叶子节点存储索引,每次读取磁盘页时就会读取一整个节点,每个叶子节点还要指向前后节点的指针,其目的是最大限度地降低磁盘io
数据在内存中读取 耗费时间是磁盘IO读取的百万分之一,而Redis是内存中读取数据、不涉及IO,因此使用了跳表,跳表模型是更快更简单的方式
- 时间复杂度优势:跳表是一种基于链表的数据结构,可以在O(log n)的时间内进行插入、删除和查找操作。而B树需要维护平衡,操作的时间复杂度较高,通常为O(log n)或者更高。在绝大多数情况下,跳表的性能要优于B树。
- 简单高效:跳表的实现相对简单,并且容易理解和调试。相比之下,B树的实现相对复杂一些,需要处理更多的情况,例如节点的分裂和合并等操作。
- 空间利用率高:在关键字比较少的情况下,跳表的空间利用率要优于B树。B树通常需要每个节点存储多个关键字和指针,而跳表只需要每个节点存储一个关键字和一个指针。
- 并发性能好:跳表的插入和删除操作比B树更加简单,因此在并发环境下更容易实现高性能。在多线程读写的情况下,跳表能够提供较好的并发性能。
Hash、B+树、跳表的比较
| 数据结构 | 实现原理 | key查询方式 | 查找效率 | 存储大小 | 插入、删除效率 |
|---|---|---|---|---|---|
| Hash | 哈希表 | 支持单key | 接近O(1) | 小,除了数据没有额外的存储 | O(1) |
| B+树 | 平衡二叉树扩展而来 | 单key,范围,分页 | O(logn) | 除了数据,还多了左右指针,以及叶子节点指针 | O(logn),需要调整树的结构,算法比较复杂 |
| 跳表 | 有序链表扩展而来 | 单key,分页 | O(logn) | 除了数据,还多了指针,但是每个节点的指针小于<2,所以比B+树占用空间小 | O(logn),只用处理链表,算法比较简单 |
Redis的过期删除策略
Redis 是可以对 key 设置过期时间的,因此需要有相应的机制将已过期的键值对删除,而做这个工作的就是过期键值删除策略
Redis整体的删除策略是惰性删除+定期删除这两种策略配合使用
什么是惰性删除
惰性删除的做法是: 不主动删除过期Key,每次从数据库访问Key时,都检测Key是否过期,如果过期就删除该Key
- 惰性删除优点:
- 对CPU时间友好,节省资源,防止短时间占用大量资源。
- 惰性删除缺点:
- 冷数据难以被删除,甚至一直留存在内存中,造内存空间浪费。
什么是定期删除
定期删除的策略是: 每隔一段时间随机从数据库中取出一批数据进行检查,并删除其中过期的Key
- 定时serverCron方法去执行清理,执行频率根据redis.conf中的hz配置的值
- 执行清理的时候,不是去扫描所有的key,而是去扫描所有设置了过期时间的key(redisDb.expires)
- 如果每次去把所有过期的key都拿过来,那么假如过期的key很多,就会很慢,所以也不是一次性拿取所有的key
- 根据hash桶的维度去扫描key,扫到20(可配)个key为止。假如第一个桶是15个key ,没有满足20,继续扫描第二个桶,第二个桶20个key,由于是以hash桶的维度扫描的,所以第二个扫到了就会全扫,总共扫描35个key
- 找到扫描的key里面过期的key,并进行删除
- 删除完检查过期的 key 超过 25%,继续执行4、5步

redis内存淘汰策略
我们设置完redis内存之后,我们就像里面放数据,但是内存总有满的时候,满的时候redis又是怎么处理的呢?
每进行一次redis操作的时候,redis都会检测可用内存,判断是否要进行内存淘汰,当超过可用内存的时候,redids 就会使用对应淘汰策略。
有以下几种内存淘汰策略:
1.no-envicition:
该策略对于写请求不再提供服务,会直接返回错误,当然排除del等特殊操作,redis默认是no-envicition策略。
2.allkeys-random:
从redis中随机选取key进行淘汰
3.allkeys-lru:
使用LRU(Least Recently Used,最近最少使用)算法,从redis中选取使用最少的key进行淘汰
4.volatile-random:
从redis中设置过过期时间的key,进行随机淘汰
5.volatile-ttl:
从redis中选取即将过期的key,进行淘汰
6.volatile-lru:
使用LRU(Least Recently Used,最近最少使用)算法,从redis中设置过过期时间的key中,选取最少使用的进行淘汰
7.volatile-lfu:
使用LFU(Least Frequently Used,最不经常使用),从设置了过期时间的键中选择某段时间之内使用频次最小的键值对清除掉
8.allkeys-lfu:
使用LFU(Least Frequently Used,最不经常使用),从所有的键中选择某段时间之内使用频次最少的键值对清除
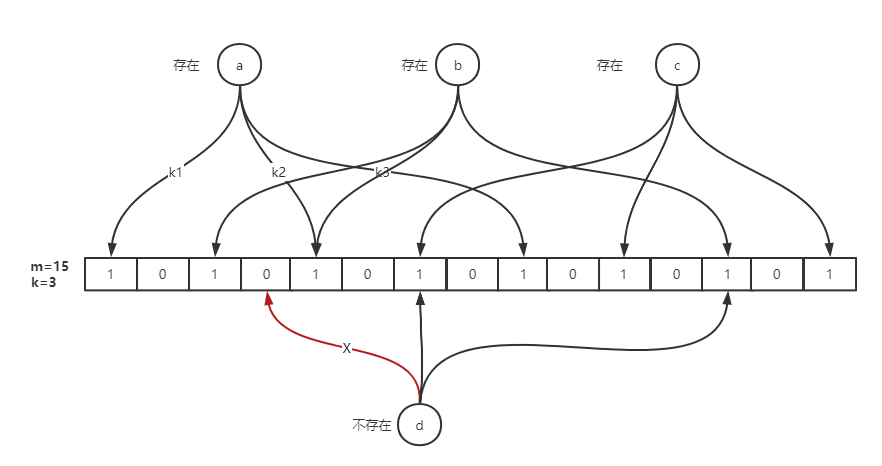
布隆过滤器原理
布隆过滤器的原理是,当一个元素被加入集合时,通过 K 个散列函数 将这个元素映射成一个位数组中的 K 个点,把它们置为 1。检索时,我们只要看看这些点是不是都是 1 就可以判断该元素“可能存在于集合中”。如果这些点中有任何一个为 0,则该元素“肯定不存在于集合中”。这种数据结构通过多个哈希函数来减少误判的概率,但仍然可能存在假阳性的情况。布隆过滤器是一种高效的空间节省的数据结构,特别适用于需要快速判断元素存在性的场景。