2025-03-20-02
This commit is contained in:
127
技术/Go/算法相关.md
127
技术/Go/算法相关.md
@@ -3,6 +3,133 @@
|
|||||||
2^x = 1 << x
|
2^x = 1 << x
|
||||||
x/2 x >> 1
|
x/2 x >> 1
|
||||||
~~~
|
~~~
|
||||||
|
## 快乐数
|
||||||
|
~~~ go
|
||||||
|
func isHappy(n int) bool {
|
||||||
|
slow, fast := n, step(n)
|
||||||
|
for fast != 1 && slow != fast {
|
||||||
|
slow = step(slow)
|
||||||
|
fast = step(step(fast))
|
||||||
|
}
|
||||||
|
return fast == 1
|
||||||
|
}
|
||||||
|
|
||||||
|
func step(n int) int {
|
||||||
|
sum := 0
|
||||||
|
for n > 0 { //通过循环逐位计算
|
||||||
|
sum += (n%10) * (n%10)
|
||||||
|
n = n/10
|
||||||
|
}
|
||||||
|
return sum
|
||||||
|
}
|
||||||
|
~~~
|
||||||
|
|
||||||
|
## 查找二维数组
|
||||||
|
~~~ go
|
||||||
|
func searchMatrix(matrix [][]int, target int) bool {
|
||||||
|
row := sort.Search(len(matrix), func(i int) bool { return matrix[i][0] > target }) - 1
|
||||||
|
if row < 0 {
|
||||||
|
return false
|
||||||
|
}
|
||||||
|
col := sort.SearchInts(matrix[row], target)
|
||||||
|
return col < len(matrix[row]) && matrix[row][col] == target
|
||||||
|
}
|
||||||
|
~~~
|
||||||
|
|
||||||
|
## LRU缓存
|
||||||
|
~~~ go
|
||||||
|
// 定义LRU缓存结构体,包含当前大小、最大容量、键值对映射表以及双向链表的头尾节点
|
||||||
|
type LRUCache struct {
|
||||||
|
size int // 当前缓存中元素的数量
|
||||||
|
capacity int // 缓存的最大容量
|
||||||
|
cache map[int]*DLinkedNode // 键到节点的映射表,用于快速查找节点
|
||||||
|
head, tail *DLinkedNode // 双向链表的虚拟头节点和虚拟尾节点,便于操作边界条件
|
||||||
|
}
|
||||||
|
|
||||||
|
// 定义双向链表节点结构体,包含键、值以及前后指针
|
||||||
|
type DLinkedNode struct {
|
||||||
|
key, value int // 节点存储的数据键和值
|
||||||
|
prev, next *DLinkedNode // 指向前一个和后一个节点的指针
|
||||||
|
}
|
||||||
|
|
||||||
|
// 初始化一个双向链表节点,仅设置键和值,前后指针默认为nil
|
||||||
|
func initDLinkedNode(key, value int) *DLinkedNode {
|
||||||
|
return &DLinkedNode{
|
||||||
|
key: key,
|
||||||
|
value: value,
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
// 构造函数,创建一个新的LRU缓存实例,并初始化其内部数据结构
|
||||||
|
func Constructor(capacity int) LRUCache {
|
||||||
|
l := LRUCache{
|
||||||
|
cache: make(map[int]*DLinkedNode), // 初始化键值对映射表
|
||||||
|
head: initDLinkedNode(0, 0), // 创建虚拟头节点
|
||||||
|
tail: initDLinkedNode(0, 0), // 创建虚拟尾节点
|
||||||
|
capacity: capacity, // 设置缓存最大容量
|
||||||
|
}
|
||||||
|
l.head.next = l.tail // 将虚拟头节点指向虚拟尾节点
|
||||||
|
l.tail.prev = l.head // 将虚拟尾节点指向虚拟头节点
|
||||||
|
return l // 返回构造好的LRU缓存实例
|
||||||
|
}
|
||||||
|
|
||||||
|
// 根据给定键从LRU缓存中获取对应的值,如果不存在则返回-1
|
||||||
|
func (this *LRUCache) Get(key int) int {
|
||||||
|
if _, ok := this.cache[key]; !ok { // 判断键是否存在于缓存中
|
||||||
|
return -1 // 如果不存在,直接返回-1
|
||||||
|
}
|
||||||
|
node := this.cache[key] // 获取到对应节点
|
||||||
|
this.moveToHead(node) // 将该节点移动到链表头部(表示最近访问)
|
||||||
|
return node.value // 返回节点的值
|
||||||
|
}
|
||||||
|
|
||||||
|
// 向LRU缓存中添加或更新键值对,如果缓存已满,则移除最久未使用的节点
|
||||||
|
func (this *LRUCache) Put(key int, value int) {
|
||||||
|
if _, ok := this.cache[key]; !ok { // 判断键是否已经存在于缓存中
|
||||||
|
node := initDLinkedNode(key, value) // 创建新节点
|
||||||
|
this.cache[key] = node // 将新节点加入到映射表中
|
||||||
|
this.addToHead(node) // 将新节点添加到链表头部(表示最近访问)
|
||||||
|
this.size++ // 增加缓存大小计数
|
||||||
|
if this.size > this.capacity { // 如果缓存大小超过最大容量
|
||||||
|
removed := this.removeTail() // 移除链表尾部节点(最久未使用)
|
||||||
|
delete(this.cache, removed.key) // 删除映射表中对应的键值对
|
||||||
|
this.size-- // 减少缓存大小计数
|
||||||
|
}
|
||||||
|
} else { // 如果键已经存在
|
||||||
|
node := this.cache[key] // 获取到对应节点
|
||||||
|
node.value = value // 更新节点的值
|
||||||
|
this.moveToHead(node) // 将该节点移动到链表头部(表示最近访问)
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
// 将指定节点添加到双向链表头部
|
||||||
|
func (this *LRUCache) addToHead(node *DLinkedNode) {
|
||||||
|
node.prev = this.head // 设置节点的前驱为虚拟头节点
|
||||||
|
node.next = this.head.next // 设置节点的后继为原头部节点
|
||||||
|
this.head.next.prev = node // 将原头部节点的前驱指向当前节点
|
||||||
|
this.head.next = node // 将虚拟头节点的后继指向当前节点
|
||||||
|
}
|
||||||
|
|
||||||
|
// 从双向链表中移除指定节点
|
||||||
|
func (this *LRUCache) removeNode(node *DLinkedNode) {
|
||||||
|
node.prev.next = node.next // 将前驱节点的后继指向后继节点
|
||||||
|
node.next.prev = node.prev // 将后继节点的前驱指向前驱节点
|
||||||
|
}
|
||||||
|
|
||||||
|
// 将指定节点移动到双向链表头部
|
||||||
|
func (this *LRUCache) moveToHead(node *DLinkedNode) {
|
||||||
|
this.removeNode(node) // 首先移除该节点
|
||||||
|
this.addToHead(node) // 然后将其添加到链表头部
|
||||||
|
}
|
||||||
|
|
||||||
|
// 移除双向链表尾部节点并返回该节点
|
||||||
|
func (this *LRUCache) removeTail() *DLinkedNode {
|
||||||
|
node := this.tail.prev // 获取尾部节点(不包括虚拟尾节点)
|
||||||
|
this.removeNode(node) // 移除该节点
|
||||||
|
return node // 返回被移除的节点
|
||||||
|
}
|
||||||
|
~~~
|
||||||
|
|
||||||
## 加油站
|
## 加油站
|
||||||
在一条环路上有 `n` 个加油站,其中第 `i` 个加油站有汽油 `gas[i]` 升。
|
在一条环路上有 `n` 个加油站,其中第 `i` 个加油站有汽油 `gas[i]` 升。
|
||||||
|
|
||||||
|
|||||||
@@ -106,4 +106,64 @@ Redis是直接操作内存的、并不需要磁盘io;而MySQL需要去读取
|
|||||||
|---|---|---|---|---|---|
|
|---|---|---|---|---|---|
|
||||||
|Hash|哈希表|支持单key|接近O(1)|小,除了数据没有额外的存储|O(1)|
|
|Hash|哈希表|支持单key|接近O(1)|小,除了数据没有额外的存储|O(1)|
|
||||||
|B+树|平衡二叉树扩展而来|单key,范围,分页|O(logn)|除了数据,还多了左右指针,以及叶子节点指针|O(logn),需要调整树的结构,算法比较复杂|
|
|B+树|平衡二叉树扩展而来|单key,范围,分页|O(logn)|除了数据,还多了左右指针,以及叶子节点指针|O(logn),需要调整树的结构,算法比较复杂|
|
||||||
|跳表|有序链表扩展而来|单key,分页|O(logn)|除了数据,还多了指针,但是每个节点的指针小于<2,所以比B+树占用空间小|O(logn),只用处理链表,算法比较简单
|
|跳表|有序链表扩展而来|单key,分页|O(logn)|除了数据,还多了指针,但是每个节点的指针小于<2,所以比B+树占用空间小|O(logn),只用处理链表,算法比较简单
|
||||||
|
## Redis的过期删除策略
|
||||||
|
Redis 是可以对 key 设置过期时间的,因此需要有相应的机制将已过期的键值对删除,而做这个工作的就是过期键值删除策略
|
||||||
|
|
||||||
|
Redis整体的删除策略是**惰性删除+定期删除**这两种策略配合使用
|
||||||
|
|
||||||
|
### 什么是惰性删除
|
||||||
|
惰性删除的做法是:
|
||||||
|
**不主动删除过期Key,每次从数据库访问Key时,都检测Key是否过期,如果过期就删除该Key**
|
||||||
|
|
||||||
|
- 惰性删除优点:
|
||||||
|
- 对CPU时间友好,节省资源,防止短时间占用大量资源。
|
||||||
|
- 惰性删除缺点:
|
||||||
|
- 冷数据难以被删除,甚至一直留存在内存中,造内存空间浪费。
|
||||||
|
|
||||||
|
### 什么是定期删除
|
||||||
|
|
||||||
|
|
||||||
|
定期删除的策略是:
|
||||||
|
**每隔一段时间随机从数据库中取出一批数据进行检查,并删除其中过期的Key**
|
||||||
|
|
||||||
|
1. 定时serverCron方法去执行清理,执行频率根据redis.conf中的hz配置的值
|
||||||
|
2. 执行清理的时候,不是去扫描所有的key,而是去扫描所有设置了过期时间的key(redisDb.expires)
|
||||||
|
3. 如果每次去把所有过期的key都拿过来,那么假如过期的key很多,就会很慢,所以也不是一次性拿取所有的key
|
||||||
|
4. 根据hash桶的维度去扫描key,扫到20(可配)个key为止。假如第一个桶是15个key ,没有满足20,继续扫描第二个桶,第二个桶20个key,由于是以hash桶的维度扫描的,所以第二个扫到了就会全扫,总共扫描35个key
|
||||||
|
5. 找到扫描的key里面过期的key,并进行删除
|
||||||
|
6. 删除完检查过期的 key 超过 25%,继续执行4、5步
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
## redis内存淘汰策略
|
||||||
|
|
||||||
|
我们设置完redis内存之后,我们就像里面放数据,但是内存总有满的时候,满的时候redis又是怎么处理的呢?
|
||||||
|
|
||||||
|
每进行一次redis操作的时候,redis都会检测可用内存,判断是否要进行内存淘汰,当超过可用内存的时候,redids 就会使用对应淘汰策略。
|
||||||
|
|
||||||
|
有以下几种内存淘汰策略:
|
||||||
|
### 1.no-envicition:
|
||||||
|
该策略对于写请求不再提供服务,会直接返回错误,当然排除del等特殊操作,**redis默认是no-envicition**策略。
|
||||||
|
### 2.allkeys-random:
|
||||||
|
从redis中随机选取key进行淘汰
|
||||||
|
### 3.allkeys-lru:
|
||||||
|
使用LRU(Least Recently Used,最近最少使用)算法,从redis中选取使用最少的key进行淘汰
|
||||||
|
### 4.volatile-random:
|
||||||
|
从redis中设置过过期时间的key,进行随机淘汰
|
||||||
|
### 5.volatile-ttl:
|
||||||
|
从redis中选取即将过期的key,进行淘汰
|
||||||
|
### 6.volatile-lru:
|
||||||
|
使用LRU(Least Recently Used,最近最少使用)算法,从redis中设置过过期时间的key中,选取最少使用的进行淘汰
|
||||||
|
### 7.volatile-lfu:
|
||||||
|
使用LFU(Least Frequently Used,最不经常使用),从设置了过期时间的键中选择某段时间之内使用频次最小的键值对清除掉
|
||||||
|
### 8.allkeys-lfu:
|
||||||
|
使用LFU(Least Frequently Used,最不经常使用),从所有的键中选择某段时间之内使用频次最少的键值对清除
|
||||||
|
|
||||||
|
## 布隆过滤器原理
|
||||||
|
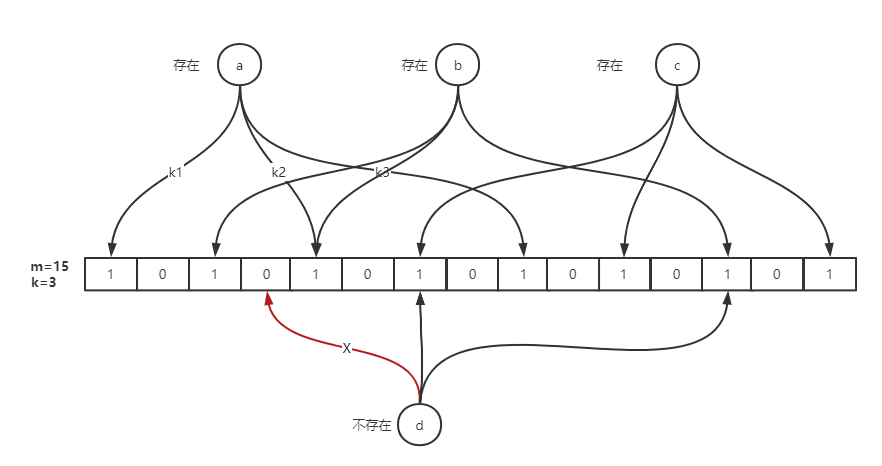
布隆过滤器的原理是,当一个元素被加入集合时,通过 **K 个散列函数** 将这个元素映射成一个位数组中的 **K 个点**,把它们置为 `1`。检索时,我们只要看看这些点是不是都是 `1` 就可以判断该元素“可能存在于集合中”。如果这些点中有任何一个为 `0`,则该元素“肯定不存在于集合中”。这种数据结构通过多个哈希函数来减少误判的概率,但仍然可能存在假阳性的情况。布隆过滤器是一种高效的空间节省的数据结构,特别适用于需要快速判断元素存在性的场景。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
##
|
||||||
69
技术/Redis/缓存设计.md
Normal file
69
技术/Redis/缓存设计.md
Normal file
@@ -0,0 +1,69 @@
|
|||||||
|
## 缓存穿透、缓存击穿、缓存雪崩
|
||||||
|
|
||||||
|
### **1. 缓存穿透**
|
||||||
|
**定义**:查询一个**不存在的数据**(如数据库中无对应记录),导致请求绕过缓存直接访问数据库,可能对数据库造成压力。
|
||||||
|
**解决方案**:
|
||||||
|
- **缓存空值**:即使查询结果为空,也将空值写入缓存并设置短过期时间,避免重复查询数据库。
|
||||||
|
- **布隆过滤器**:通过概率数据结构拦截不存在的查询请求,减少无效数据库访问。
|
||||||
|
- **请求校验**:对用户输入参数进行合法性校验(如ID格式),过滤非法请求。
|
||||||
|
|
||||||
|
### **2. 缓存击穿**
|
||||||
|
**定义**:某个**热点数据的缓存失效**,导致大量并发请求直接冲击数据库。
|
||||||
|
**解决方案**:
|
||||||
|
- **热点数据永不过期**:物理上不设置过期时间,通过后台异步更新缓存。
|
||||||
|
- **分布式锁**:缓存失效时,仅允许一个线程回源数据库更新缓存,其他线程等待。
|
||||||
|
- **预加载**:在缓存失效前主动加载数据,避免空窗期。
|
||||||
|
|
||||||
|
### **3. 缓存雪崩**
|
||||||
|
**定义**:大量缓存**同时失效**(如设置了相同过期时间),导致请求集中冲击数据库。
|
||||||
|
**解决方案**:
|
||||||
|
- **过期时间随机化**:为缓存设置基础过期时间+随机值(如1-5分钟),分散失效时间。
|
||||||
|
- **服务熔断与限流**:当数据库压力过大时,触发熔断机制或限制请求速率,保护后端系统。
|
||||||
|
- **多级缓存**:使用主备缓存(如本地缓存+Redis),主缓存失效时从备缓存或数据库加载。
|
||||||
|
- **高可用架构**:构建Redis集群或主从架构,避免单点故障导致的雪崩。
|
||||||
|
|
||||||
|
### **总结**:
|
||||||
|
- **穿透**:防无效查询,用空值缓存+布隆过滤器。
|
||||||
|
- **击穿**:保热点数据,用永不过期+锁/预加载。
|
||||||
|
- **雪崩**:分散失效时间+熔断限流+多级缓存。
|
||||||
|
|
||||||
|
|
||||||
|
## 缓存一致性
|
||||||
|
|
||||||
|
### **一、缓存一致性问题的定义与风险**
|
||||||
|
缓存与数据库数据不一致的核心矛盾在于:**非原子操作导致中间状态暴露**。
|
||||||
|
**典型问题场景**:
|
||||||
|
1. **并发写冲突**:多个请求同时修改数据,缓存与数据库更新顺序不一致(如A请求更新数据库,B请求删除缓存)。
|
||||||
|
2. **读写分离延迟**:数据库主从架构中,从库同步延迟导致缓存更新读取到旧数据。
|
||||||
|
3. **缓存失效窗口**:缓存删除后、新数据加载前的短暂时间内,请求可能读取到旧数据。
|
||||||
|
|
||||||
|
### **二、优化与解决方案**
|
||||||
|
#### **1. 延迟双删策略**
|
||||||
|
- **操作流程**:更新数据库后,**延迟删除缓存**(如等待几百毫秒),确保数据库事务提交且从库同步完成后再清理缓存,避免旧数据残留。
|
||||||
|
- **适用场景**:对一致性要求较高且能容忍短暂延迟的场景(如电商库存更新)。
|
||||||
|
|
||||||
|
#### **2. 分布式锁控制并发**
|
||||||
|
- **实现方式**:在写操作前加锁(如Redis分布式锁),确保同一时间只有一个线程执行“更新数据库+删除缓存”的流程,防止并发冲突。
|
||||||
|
- **缺点**:可能降低系统吞吐量,需权衡性能与一致性。
|
||||||
|
|
||||||
|
#### **3. 异步消息队列更新**
|
||||||
|
- **方案设计**:将数据库变更事件(如增删改)发布到消息队列,由消费者异步更新缓存,通过**最终一致性**降低直接耦合。
|
||||||
|
- **优势**:解耦系统组件,提升高并发场景下的稳定性。
|
||||||
|
|
||||||
|
#### **4. 版本号/时间戳控制**
|
||||||
|
- **实现逻辑**:为数据添加版本号或时间戳,缓存更新时校验版本,仅当缓存版本低于数据库时才更新,避免覆盖最新数据。
|
||||||
|
- **适用场景**:需要精确控制数据版本的场景(如金融交易系统)。
|
||||||
|
|
||||||
|
#### **5. 多级缓存协同更新**
|
||||||
|
- **架构设计**:结合本地缓存(如Caffeine)与分布式缓存(如Redis),通过层级失效机制(如先更新数据库,再逐级删除本地缓存和分布式缓存)减少不一致窗口。
|
||||||
|
- **示例**:更新数据库后,先删除本地缓存,再通过发布-订阅模式通知其他节点删除缓存。
|
||||||
|
|
||||||
|
#### **6. 物理删除代替更新缓存**
|
||||||
|
- **核心思想**:避免直接更新缓存(可能导致脏数据),而是通过删除缓存触发后续请求自动从数据库加载新数据。
|
||||||
|
- **实践建议**:优先使用“先更新数据库,再删除缓存”的顺序,降低数据不一致概率。
|
||||||
|
|
||||||
|
### **三、总结与权衡**
|
||||||
|
- **强一致性 vs 性能**:无法完全避免短暂不一致,需根据业务需求选择策略(如金融交易需分布式锁,电商促销可接受最终一致性)。
|
||||||
|
- **监控与优化**:通过监控缓存命中率、数据库负载等指标,动态调整过期时间、锁粒度等参数。
|
||||||
|
- **技术选型**:结合分布式缓存(如Redis集群)、消息队列(如Kafka)和一致性协议(如CPU缓存MESI协议)提升系统整体一致性。
|
||||||
|
|
||||||
Reference in New Issue
Block a user