8.2 KiB
ACID vs BASE
ACID(原子性、一致性、隔离性、持久性)和 BASE(基本可用、软状态、最终一致性)是数据库事务和系统设计的两种核心理念,分别适用于不同场景。
ACID
适用于传统关系型数据库(如 MySQL、PostgreSQL)
- 原子性(Atomicity):事务要么全部成功,要么全部失败回滚。
- 一致性(Consistency):数据始终符合预定义规则(如约束、触发器)。
- 隔离性(Isolation):并发事务互不干扰,结果等同于串行执行。
- 持久性(Durability):事务提交后数据永久保存,即使系统崩溃也不丢失。
典型场景:银行转账、订单支付、库存扣减等对数据准确性要求极高的场景。
BASE
适用于分布式 NoSQL 系统(如 Cassandra、MongoDB)
- 基本可用(Basically Available):系统即使部分故障,仍能响应请求(允许降级)。
- 软状态(Soft State):数据可能随时间变化,无需实时同步。
- 最终一致性(Eventually Consistent):数据更新会延迟同步,但最终全局一致。
典型场景:社交网络动态、电商商品浏览、日志存储等高并发、可容忍短暂不一致的场景。
核心差异
| 维度 | ACID | BASE |
|---|---|---|
| 一致性 | 强一致性(实时) | 最终一致性(延迟) |
| 优先目标 | 数据安全与准确性 | 高可用性与扩展性 |
| 适用系统 | 单机/集中式数据库 | 分布式系统(如微服务、云原生) |
| 性能特点 | 读写延迟较高,吞吐量较低 | 读写延迟低,吞吐量高 |
一句话总结:
- ACID:牺牲性能换安全,适合“钱不能错”(如银行系统)。
- BASE:牺牲强一致换高可用,适合“用户能等”(如微博评论)。
根据业务需求选择:要么严格保数据,要么灵活保体验。
索引的分类
- 按 「数据结构」 分类:B+tree索引、Hash索引、Full-text索引。
- 按 「物理存储」 分类:聚簇索引(主键索引)、二级索引(辅助索引)。
- 按 「字段特性」 分类:主键索引、唯一索引、普通索引、前缀索引。
- 按 「字段个数」 分类:单列索引、联合索引。
InnoDB默认索引
在创建表时,InnoDB 存储引擎会根据不同的场景选择不同的列作为索引:
- 如果有主键,默认会使用主键作为聚簇索引的索引键(key);
- 如果没有主键,就选择第一个不包含 NULL 值的唯一列作为聚簇索引的索引键(key);
- 在上面两个都没有的情况下,InnoDB 将自动生成一个隐式自增 id (不可见的名为row_id的列名为GEN_CLUST_INDEX的聚簇索引,该列是一个6字节的自增数值) 列作为聚簇索引的索引键(key); 其它索引都属于辅助索引(Secondary Index),也被称为二级索引或非聚簇索引。创建的主键索引和二级索引默认使用的是 B+Tree 索引。
MySQL 的存储引擎有哪些?为什么常用InnoDB?
MySQL 的存储引擎常用的主要有 3 个:
- InnoDB存储引擎:支持事务处理,支持外键,支持崩溃修复能力和并发控制。如果需要对事务的完整性要求比较高(比如银行),要求实现并发控制(比如售票),那选择InnoDB有很大的优势。如果需要频繁的更新、删除操作的数据库,也可以选择InnoDB,因为支持事务的提交(commit)和回滚(rollback)。
- MyISAM存储引擎:插入数据快,空间和内存使用比较低。如果表主要是用于插入新记录和读出记录,那么选择MyISAM能实现处理高效率。如果应用的完整性、并发性要求比 较低,也可以使用。如果数据表主要用来插入和查询记录,则MyISAM引擎能提供较高的处理效率
- MEMORY存储引擎:所有的数据都在内存中,数据的处理速度快,但是安全性不高。如果需要很快的读写速度,对数据的安全性要求较低,可以选择MEMOEY。它对表的大小有要求,不能建立太大的表。所以,这类数据库只使用在相对较小的数据库表。如果只是临时存放数据,数据量不大,并且不需要较高的数据安全性,可以选择将数据保存在内存中的Memory引擎,MySQL中使用该引擎作为临时表,存放查询的中间结果 常用InnoDB的原因是支持事务,且最小锁的粒度是行级锁。
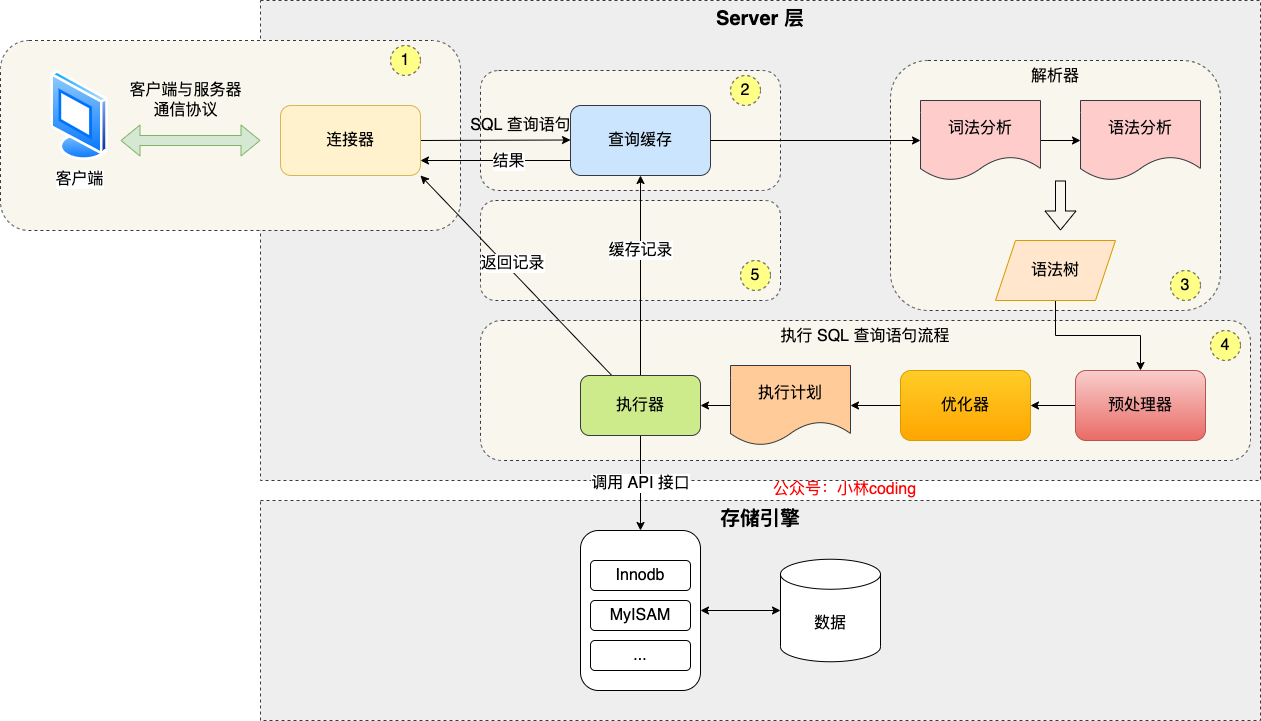
执行一条 SQL 查询语句,期间发生了什么?
- 连接器:建立连接,管理连接、校验用户身份;
- 查询缓存:查询语句如果命中查询缓存则直接返回,否则继续往下执行。MySQL 8.0 已删除该模块;
- 解析 SQL,通过解析器对 SQL 查询语句进行词法分析、语法分析,然后构建语法树,方便后续模块读取表名、字段、语句类型;
- 执行 SQL:执行 SQL 共有三个阶段:
- 预处理阶段:检查表或字段是否存在;将 select * 中的 * 符号扩展为表上的所有列。
- 优化阶段:基于查询成本的考虑, 选择查询成本最小的执行计划;
- 执行阶段:根据执行计划执行 SQL 查询语句,从存储引擎读取记录,返回给客户端;
MySQL 的 NULL 值是怎么存放的?
MySQL 的 Compact 行格式中会用「NULL值列表」来标记值为 NULL 的列,NULL 值并不会存储在行格式中的真实数据部分。
NULL值列表会占用 1 字节空间,当表中所有字段都定义成 NOT NULL,行格式中就不会有 NULL值列表,这样可节省 1 字节的空间。
MySQL 怎么知道 varchar(n) 实际占用数据的大小?
MySQL 的 Compact 行格式中会用「变长字段长度列表」存储变长字段实际占用的数据大小。
varchar(n) 中 n 最大取值为多少?
一行记录最大能存储 65535 字节的数据,但是这个是包含「变长字段字节数列表所占用的字节数」和「NULL值列表所占用的字节数」。所以, 我们在算 varchar(n) 中 n 最大值时,需要减去这两个列表所占用的字节数。
如果一张表只有一个 varchar(n) 字段,且允许为 NULL,字符集为 ascii。varchar(n) 中 n 最大取值为 65532。
计算公式:65535 - 变长字段字节数列表所占用的字节数 - NULL值列表所占用的字节数 = 65535 - 2 - 1 = 65532。
如果有多个字段的话,要保证所有字段的长度 + 变长字段字节数列表所占用的字节数 + NULL值列表所占用的字节数 <= 65535。
行溢出后,MySQL 是怎么处理的?
如果一个数据页存不了一条记录,InnoDB 存储引擎会自动将溢出的数据存放到「溢出页」中。
Compact 行格式针对行溢出的处理是这样的:当发生行溢出时,在记录的真实数据处只会保存该列的一部分数据,而把剩余的数据放在「溢出页」中,然后真实数据处用 20 字节存储指向溢出页的地址,从而可以找到剩余数据所在的页。
Compressed 和 Dynamic 这两种格式采用完全的行溢出方式,记录的真实数据处不会存储该列的一部分数据,只存储 20 个字节的指针来指向溢出页。而实际的数据都存储在溢出页中。
B+索引

相比于标准的B+树,InnoDB使用的B+树有如下特点:
- B+ 树的叶子节点之间是用「双向链表」进行连接,既能向右遍历、也能向左遍历
- B+ 树点节点内容是数据页,数据页里存放了用户的记录以及各种信息,每个数据页默认大小是 16 KB